
We have worked on several AI computer vision models, some for research and others for production. We have experience in building new models so the IP is owned by the client, and also using open source models.
AI Video Upscaler
Trained on dashcam footage, the upscale doubles the resolution of the input video, reduces video compression artifacts and sharpens the video without over sharpening road signs. We experimented with various commercial solutions before taking an open source engine and creating our own training data set optimised for dashcam footage.
Pseudo Lidar from a monocular camera
This project is a work in progress, the goal is to have a camera agnostic video input, and to detect and map the position and orientation of other vehicles relative to the camera position. The ultimate goal is to create a “Tesla” style 3d map reconstruction display in the UI.

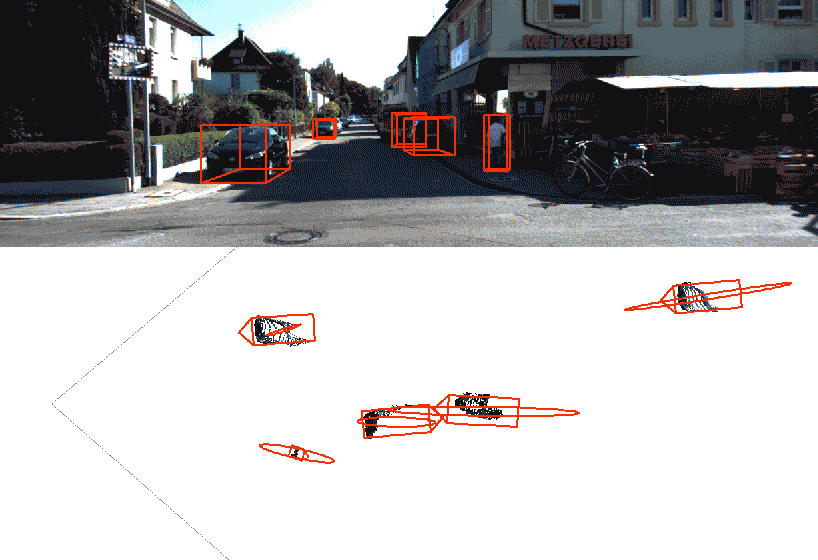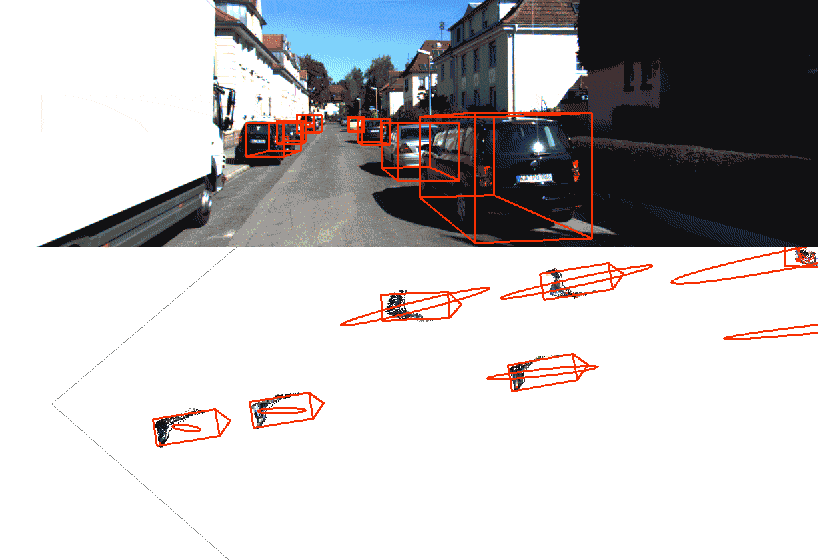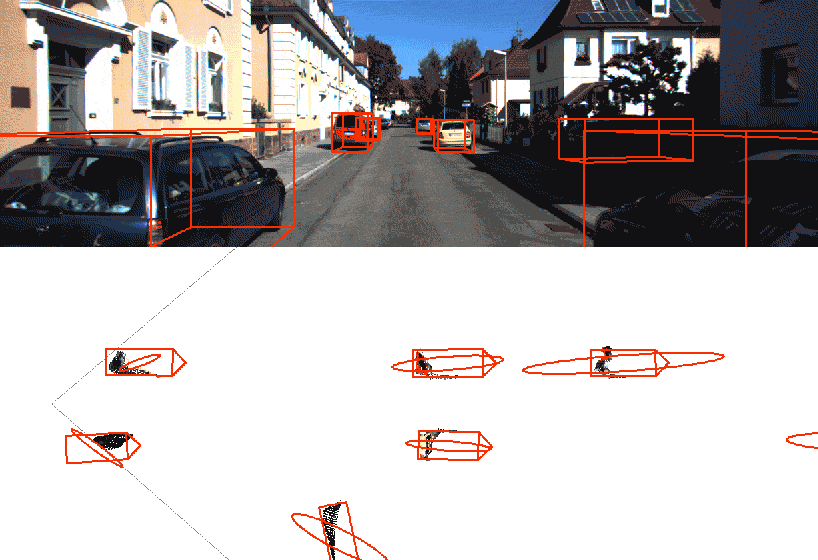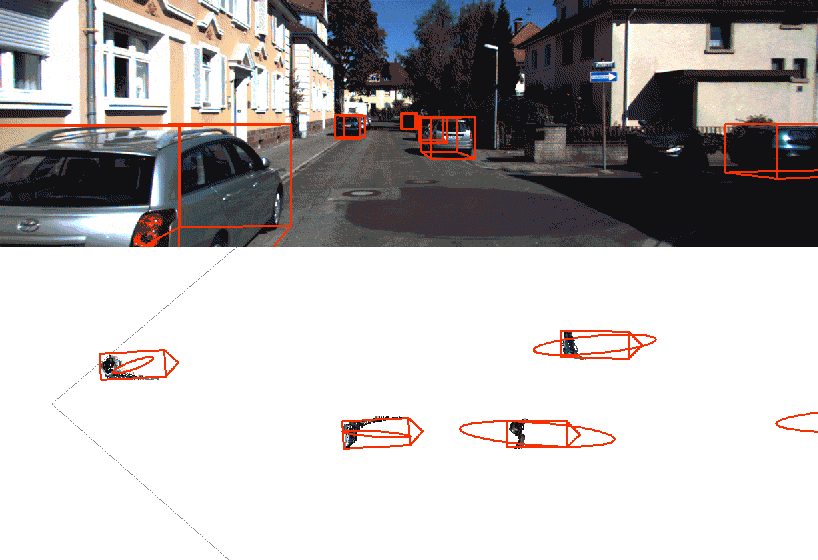
Video object detection and segmentation
This model is based on YOLO “You only look once” an Detectron object segmentation to create visually impressive AI video overlays. When combined with AI meta data from supported cameras, we can additionally generate context specific overlays such as forward collision warnings, where the warning and the measurement is overlaid in the video scene.
Dashboard detection & segmentation
In order to render the overlay for the following distance on the video, it is necessary to detect if the vehicle dashboard/hood is visible in the video and if so to segment it as a polygon so the video renderer can subtract this mask from the road overlay resulting in a much higher quality end result.
We created our own training dataset and then trained our own image segmentation model



